Image Recognition on Nicla

This project involved developing a person detection model using the Arduino Nicla Vision and exploring the impact of data quality on model performance. The goal was to understand the influence of data quantity and other factors on the model.
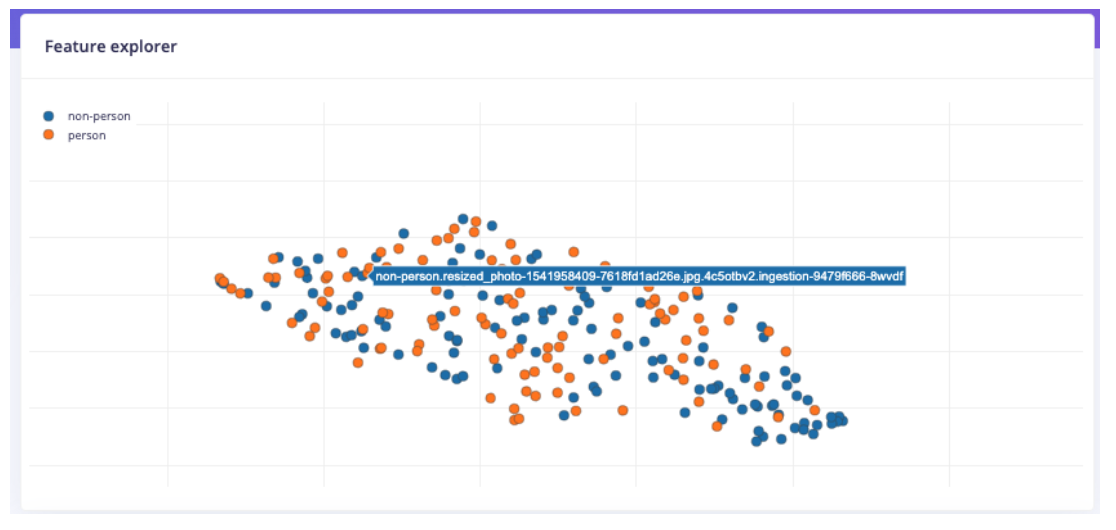
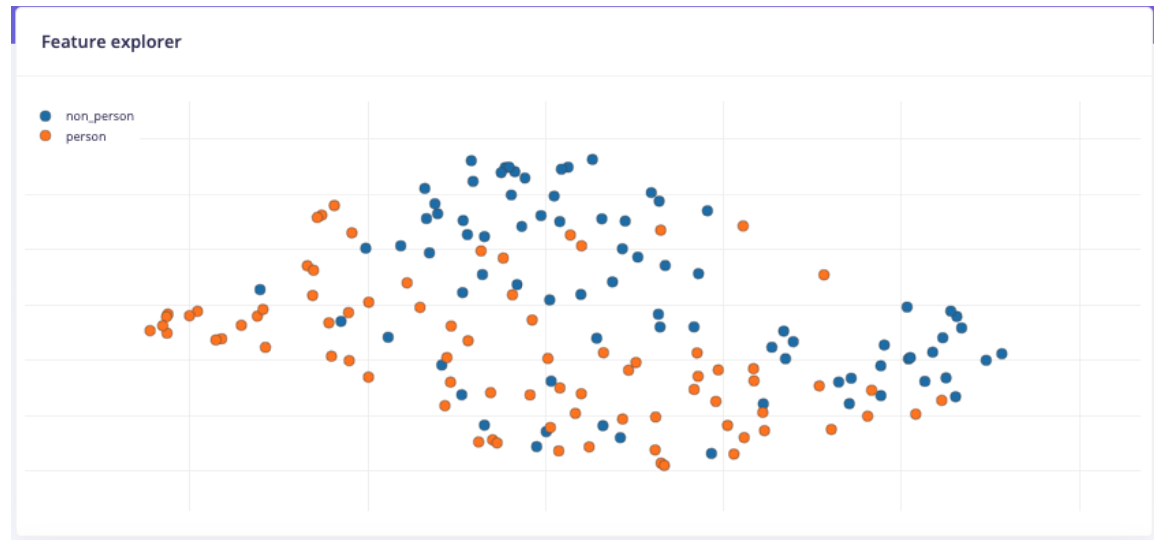
The project began by experimenting with the number of person and non-person images in the dataset. It was observed that increasing the number of images on one side of the dataset made their cluster more prominent, while increasing both sides led to merged clusters. It was hypothesized that accuracy would correlate with how distinct the clusters were in the feature explorer, suggesting that more images would build more accurate clusters and that distinguishing the clusters would be important.
- An initial dataset was created from the "Annotated Faces in the Wild" dataset, with 100 person and 100 non-person images, downsized to 96 x 96 resolution
- After labeling and splitting the dataset, the feature explorer did not show a strong decision boundary
- The model trained on this dataset had a low accuracy of 60% on non-person and 66.7% on person
To improve the distinction between person and non-person clusters, the project then focused on using images taken by the Nicla, because the test set contained Nicla images. It was decided that focusing on faces as the key feature for person images would make the model more robust, avoiding the complexity of including full body shapes and clothing.
- Photos with semi-bright and semi-dark lighting were used
- Non-human objects with human-like shapes were included to help with non-person identification
- A second dataset was created with 100 photos each of people and non-persons using the Nicla
- This resulted in a stronger decision boundary and better accuracy (76.9% for person and 94.7% for non-persons)
- However, adding in the previous online dataset dropped the accuracy for persons down to 56.5%, while maintaining a similar accuracy of 98.4% for non-persons
- This drop was attributed to the Nicla person photos being too "nice" and failing to recognize images with cut-off faces
The final dataset combined 100 non-person images from the second dataset, and 100 person images split between 25 from the second and 75 from the first.
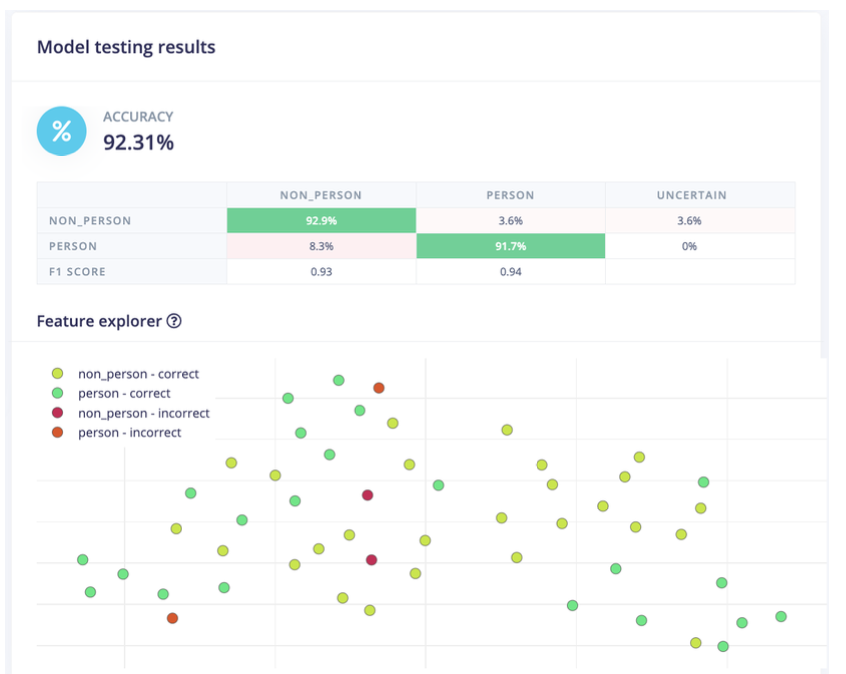
- This final dataset yielded a test accuracy of 85% on persons and 90% on non-persons
- On a larger set combining both datasets, it scored a test accuracy of 91.7% for persons and 92.9% for non-persons