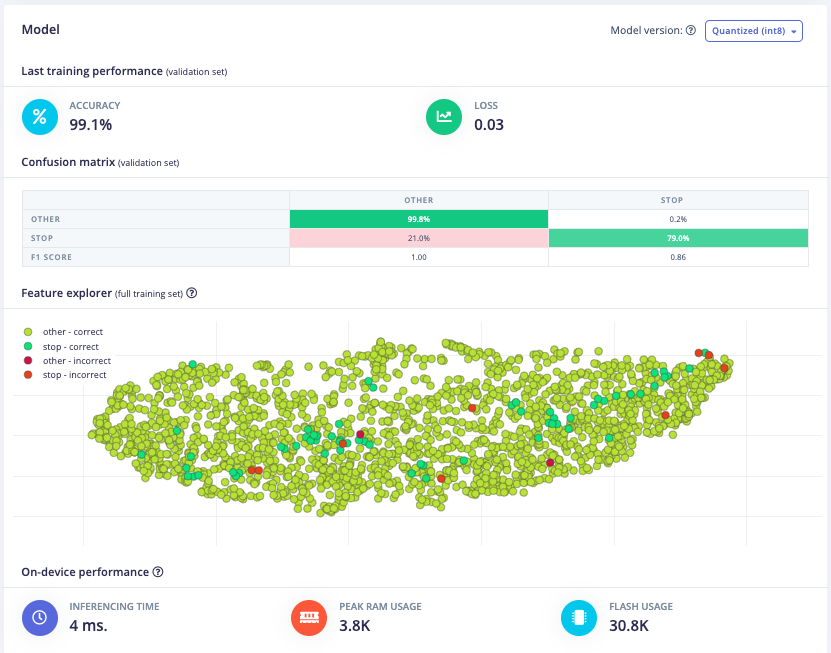
Keyword Spotting on Arduino Nicla
I developed an end-to-end keyword spotting (KWS) model using Edge Impulse and deployed it on the Arduino Nicla Vision, gaining hands-on experience in data preprocessing, model optimization, and embedded deployment. In the first phase, I created an Edge Impulse project and uploaded the Google Speech Commands (GSC) dataset, a widely used dataset in the TinyML community. I then extracted Mel-Frequency Cepstral Coefficients (MFCC) features from audio samples and trained an initial classification model for keyword spotting the word "stop". Once trained, I deployed the model to the Nicla Vision using the Arduino IDE, ensuring it could perform real-time keyword detection on an embedded device.
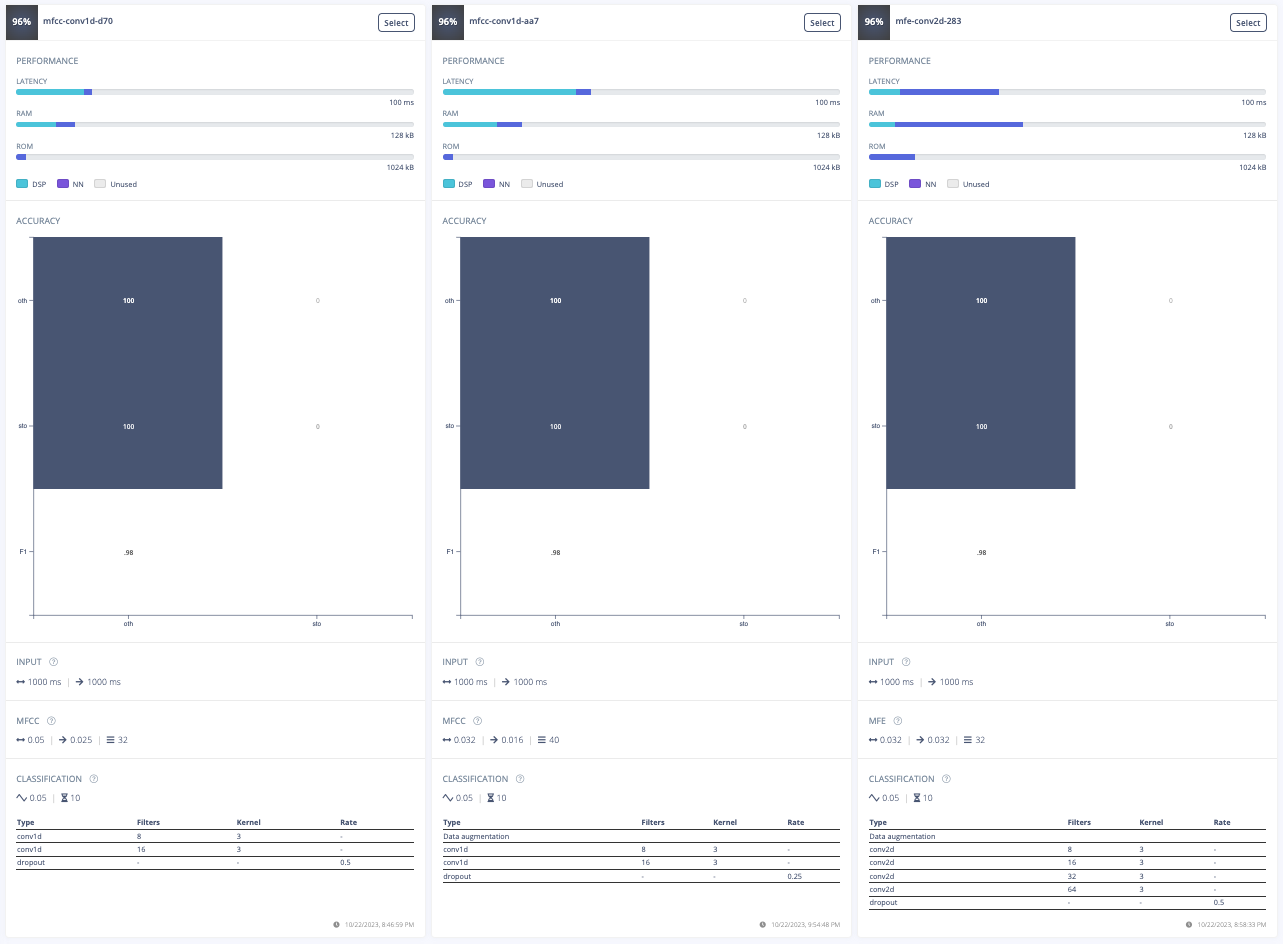
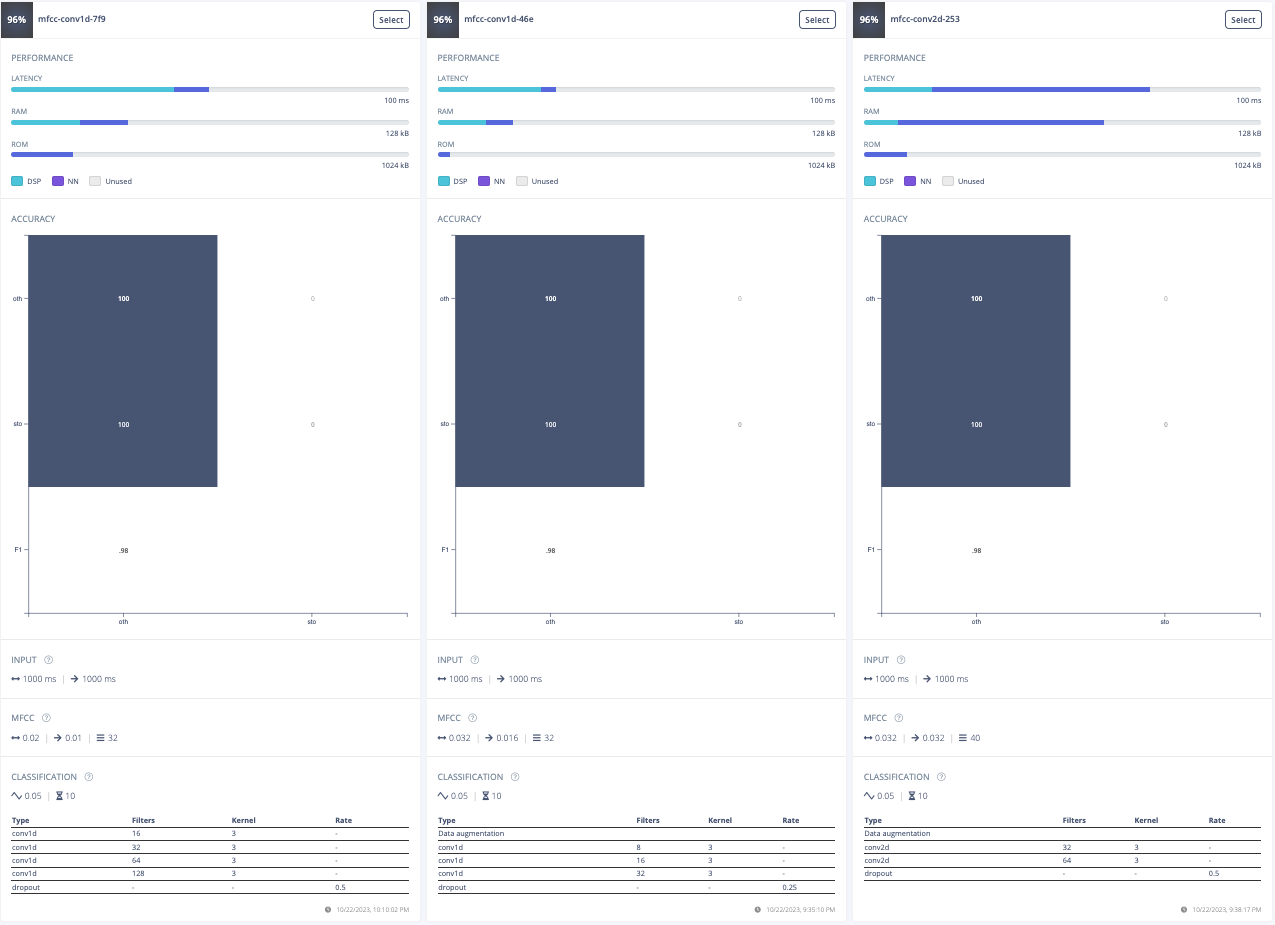
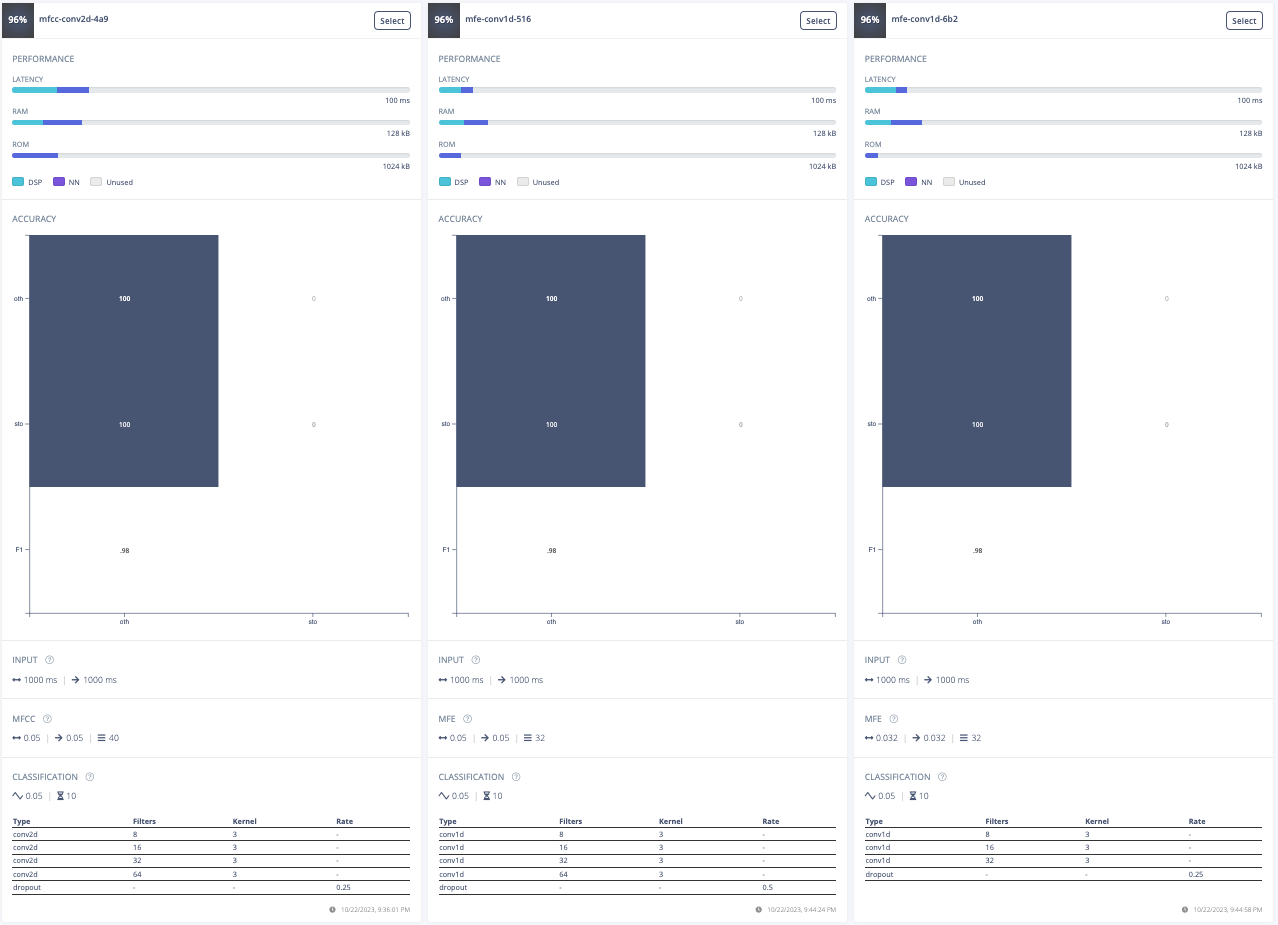
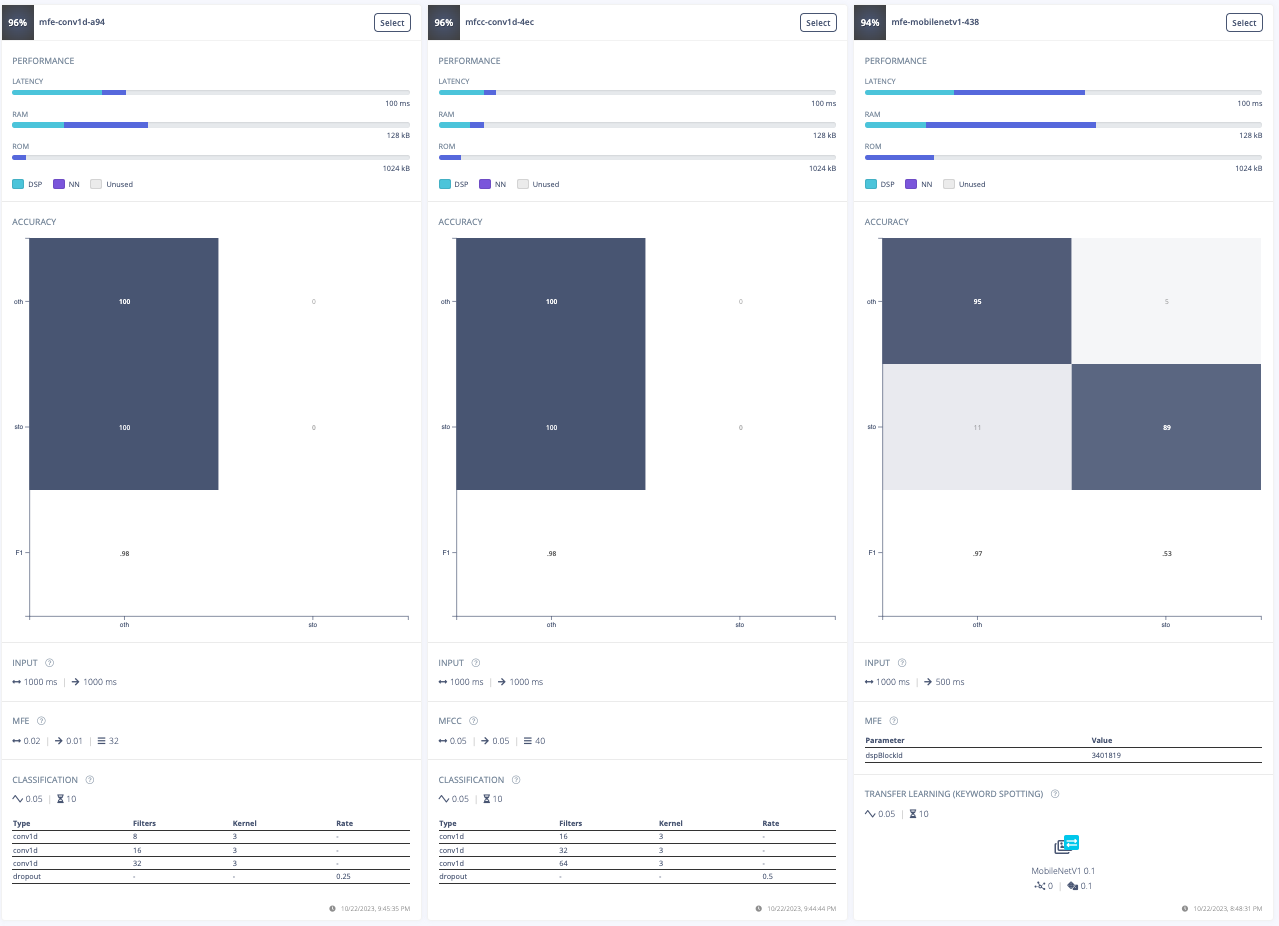
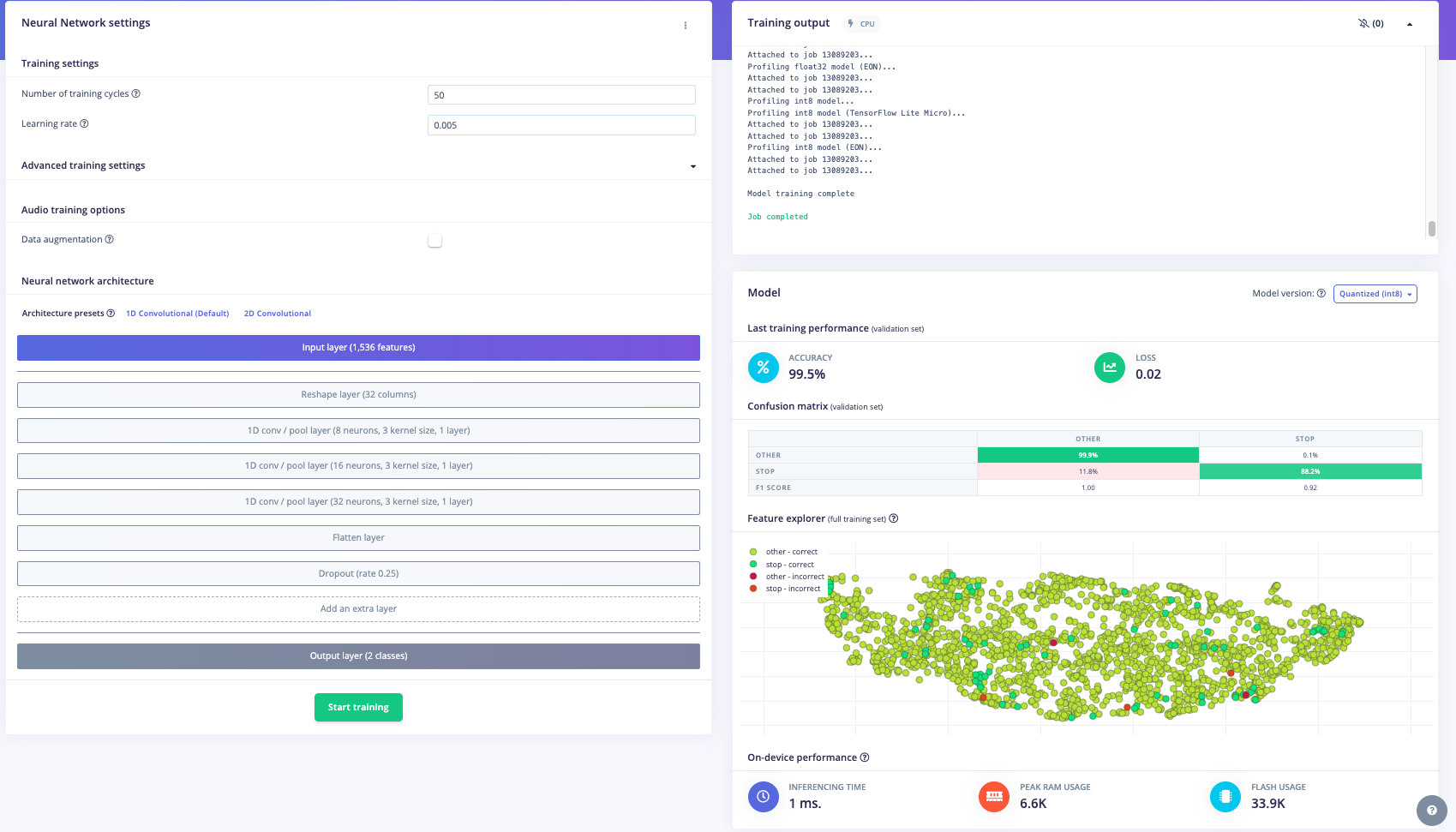
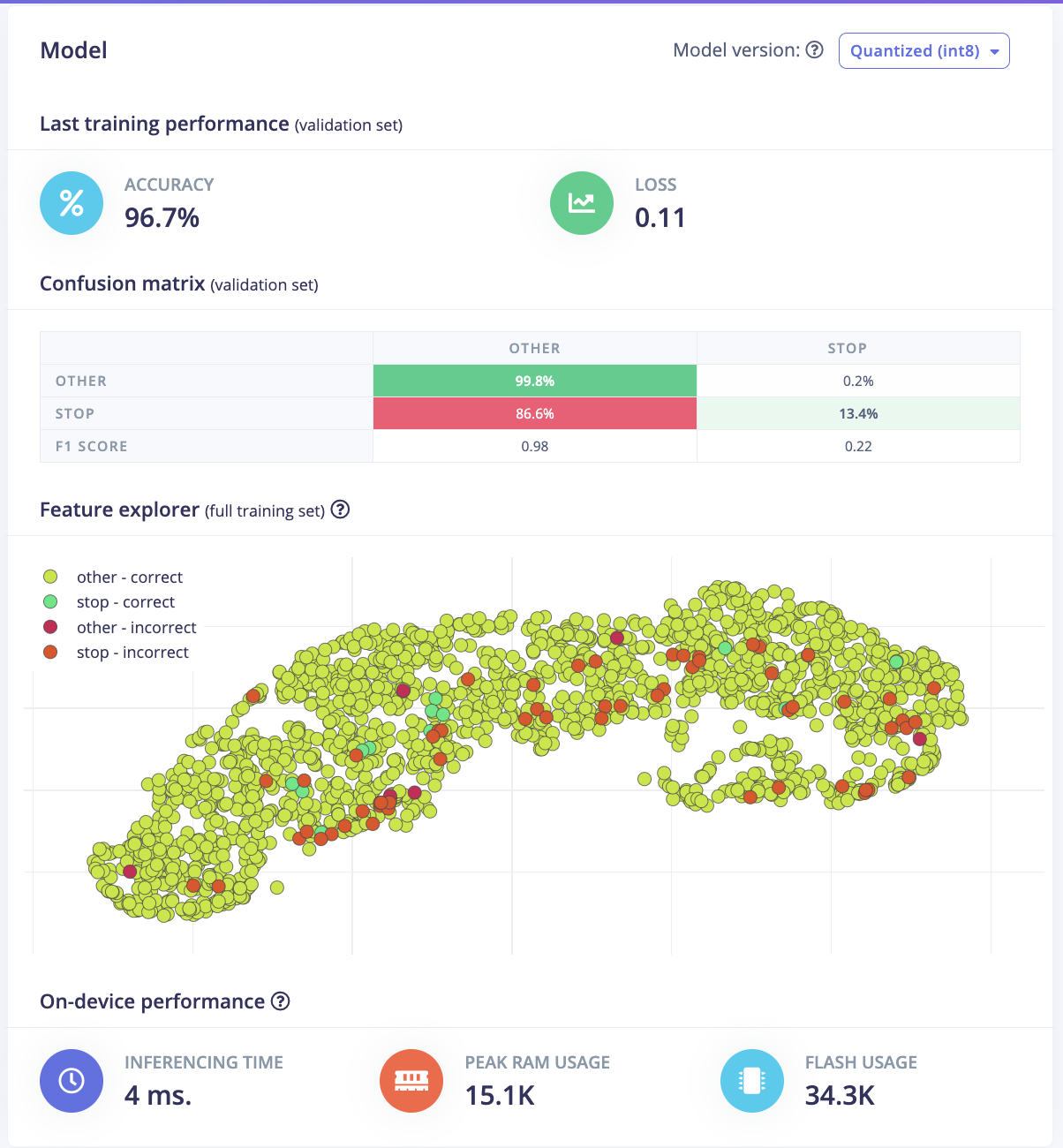
For this project, the goal was to train a model to spot the keyword "stop". The initial approach involved experimenting with different data preprocessing techniques. The first attempt was changing the input format from MFE to spectrogram which had poor results. Then, the frame length was increased from 0.05 to 0.5 which improved the model's accuracy, inferencing time, peak RAM usage, and flash storage. Further adjustments included increasing the frame stride to 0.5, which resulted in decreased accuracy but also reduced peak RAM usage and finally, the filter number was increased from 32 to 42 which also resulted in lower accuracy. After these experiments, the final data processing features were chosen.
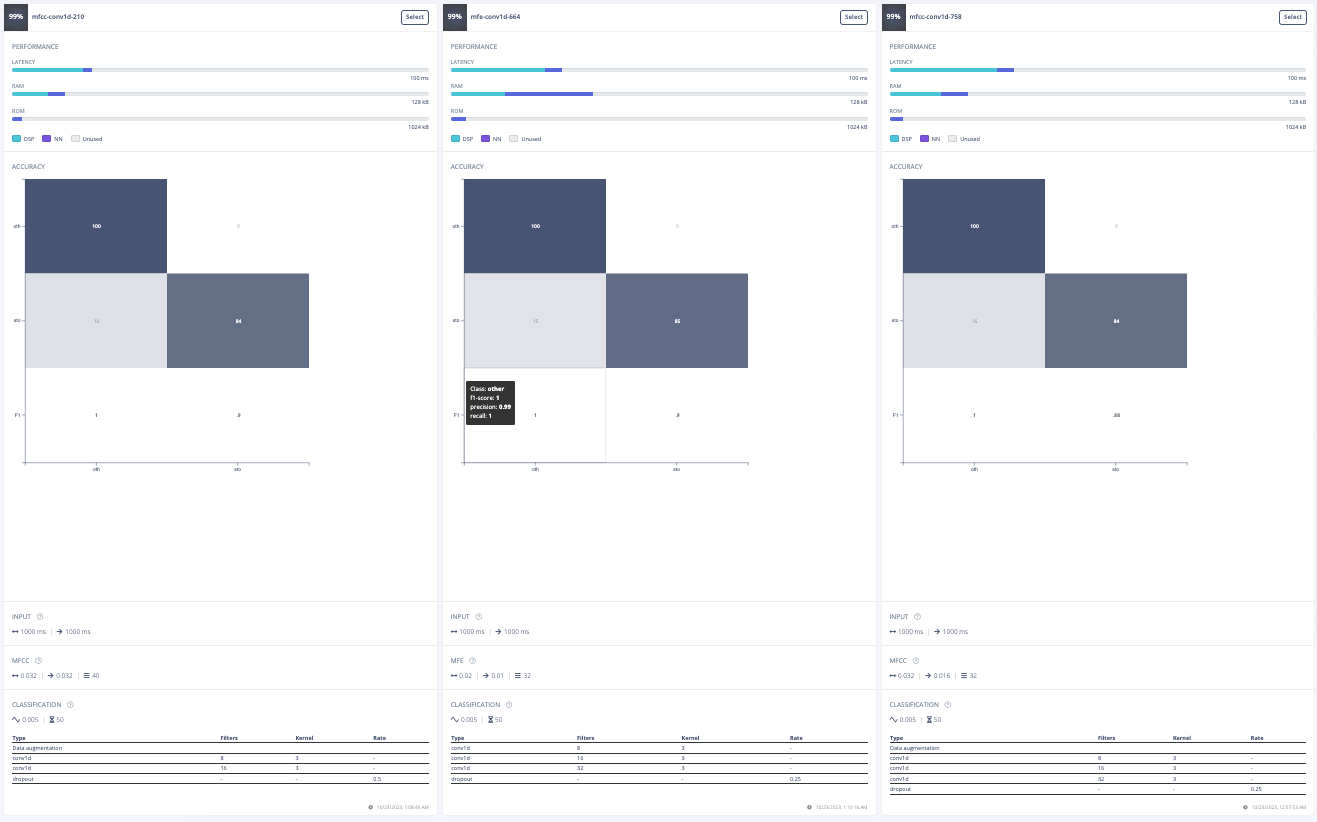
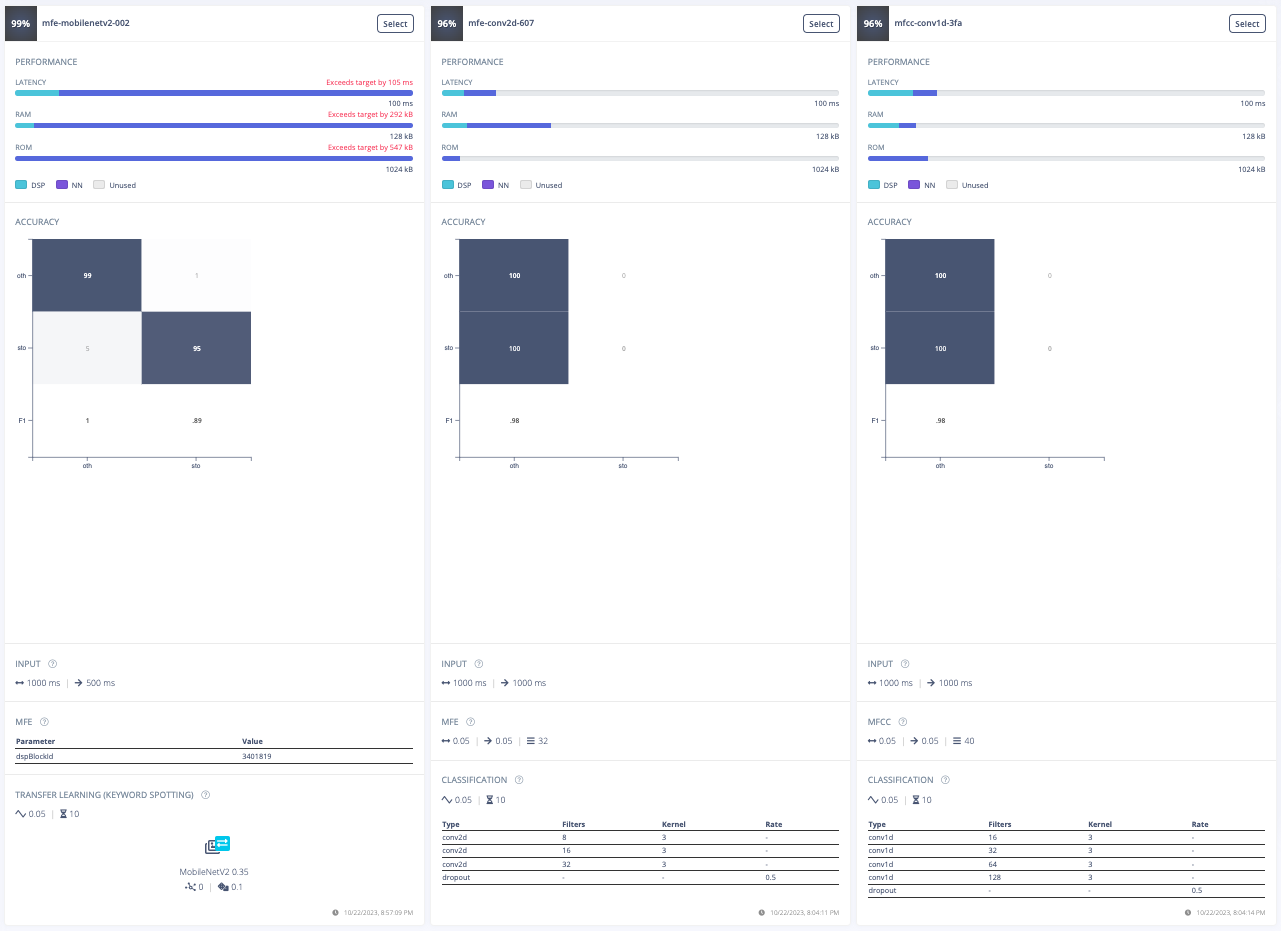
Furthermore, a model architecture search was conducted using the EON tuner. This search revealed that mobilenet v2 was the most accurate model, but its latency, RAM, and ROM usage exceeded the set limits. Further searches for more bespoke architectures showed that conv1d models with 2-3 convolutional layers and a dropout layer at the end were the most accurate. This is likely due to the suitability of conv1d models for temporal sequences like audio and the dropout layer's ability to prevent overfitting on the unbalanced dataset. The final chosen model was a conv1d model with three layers: the first with 8 neurons, the second with 16, and the third with 32, each with a kernel size of 3 and a pooling layer. A dropout layer was included after flattening which dropped 25% of the data. This model achieved an accuracy of 88.2% for identifying "stop" and 99.9% for other keywords, with a latency of 1ms, peak RAM usage of 6.6k, and flash usage of 33.9k.
Initial Model
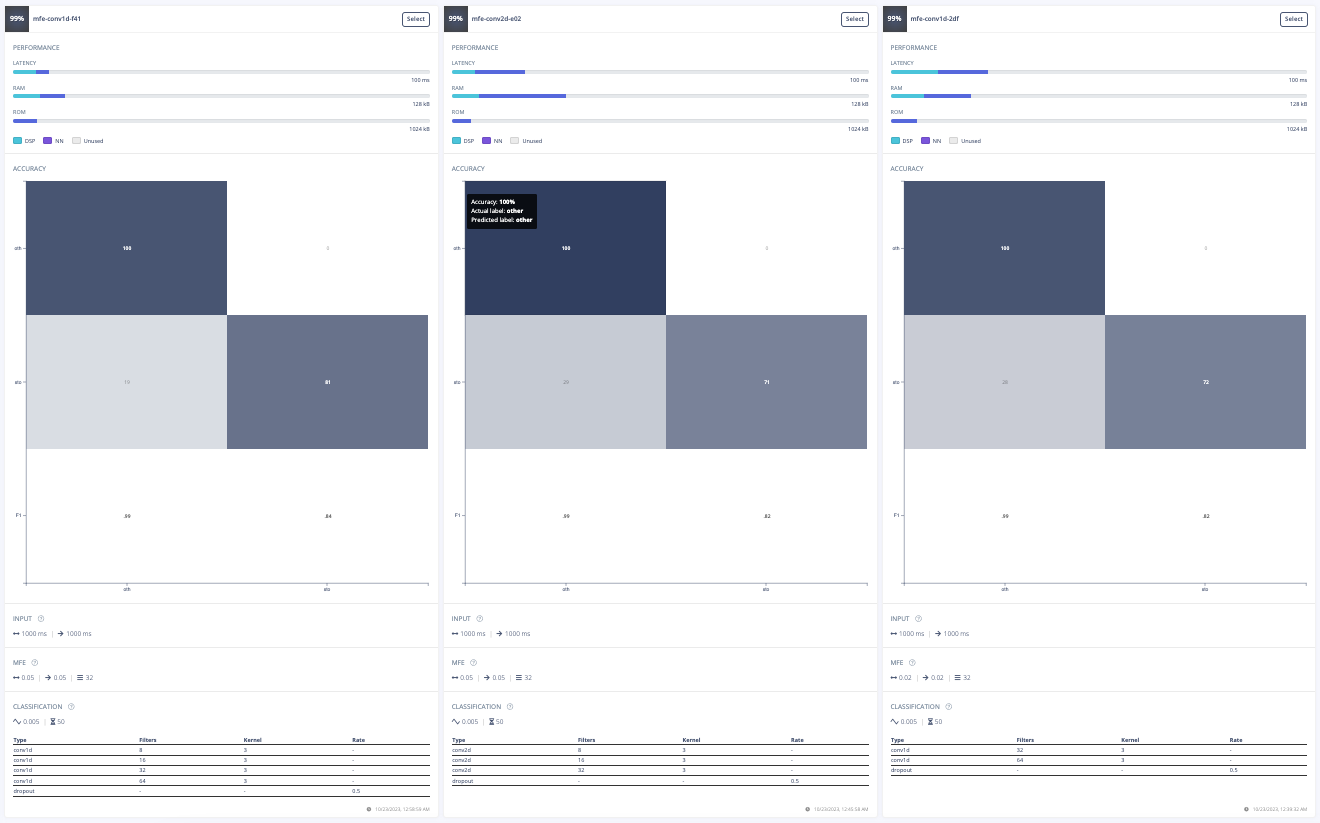
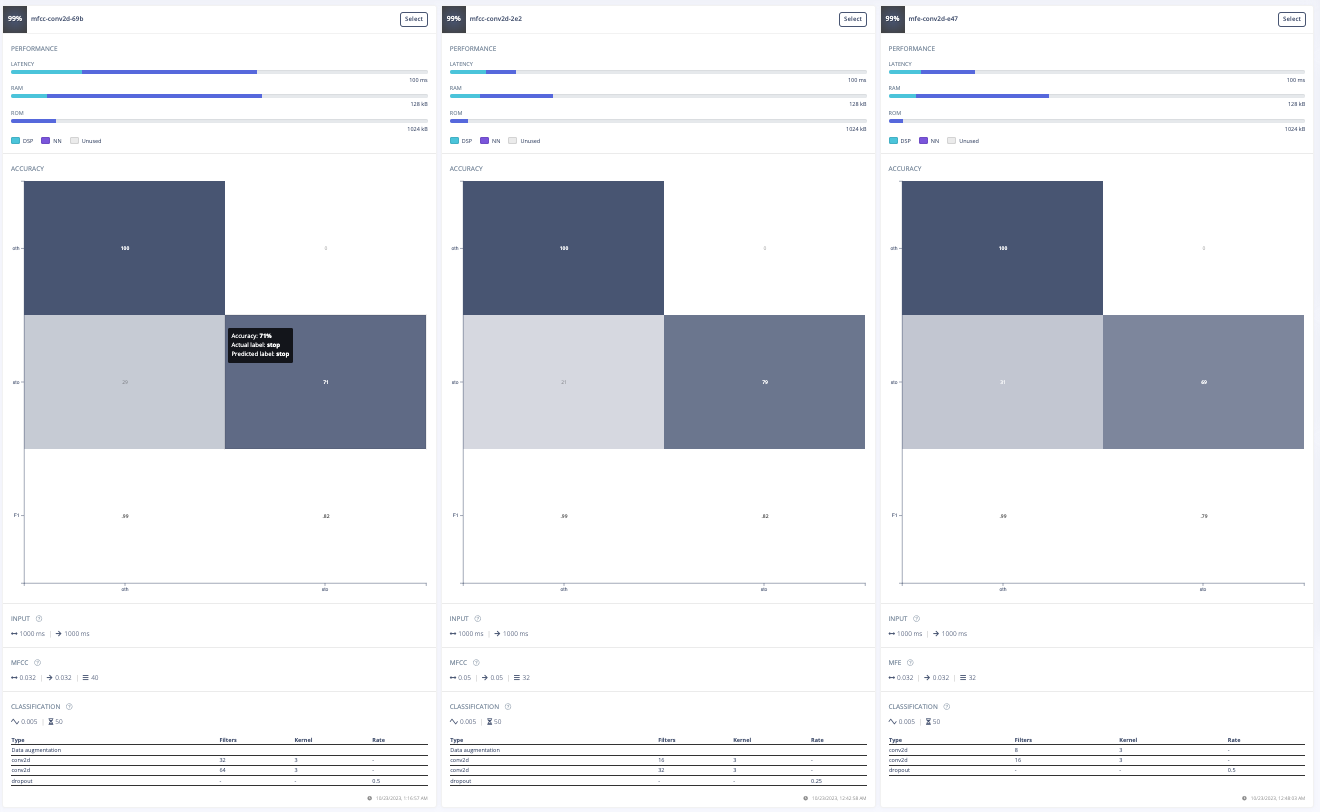
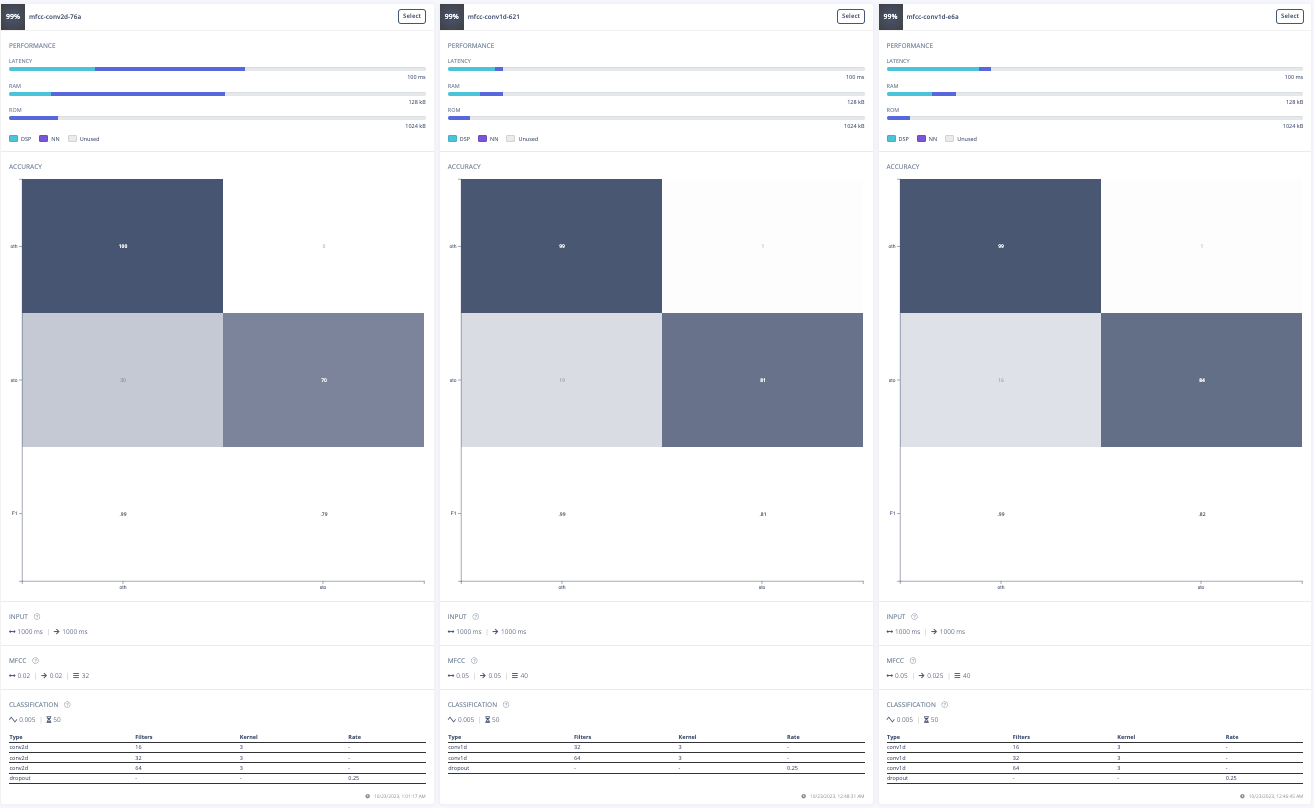
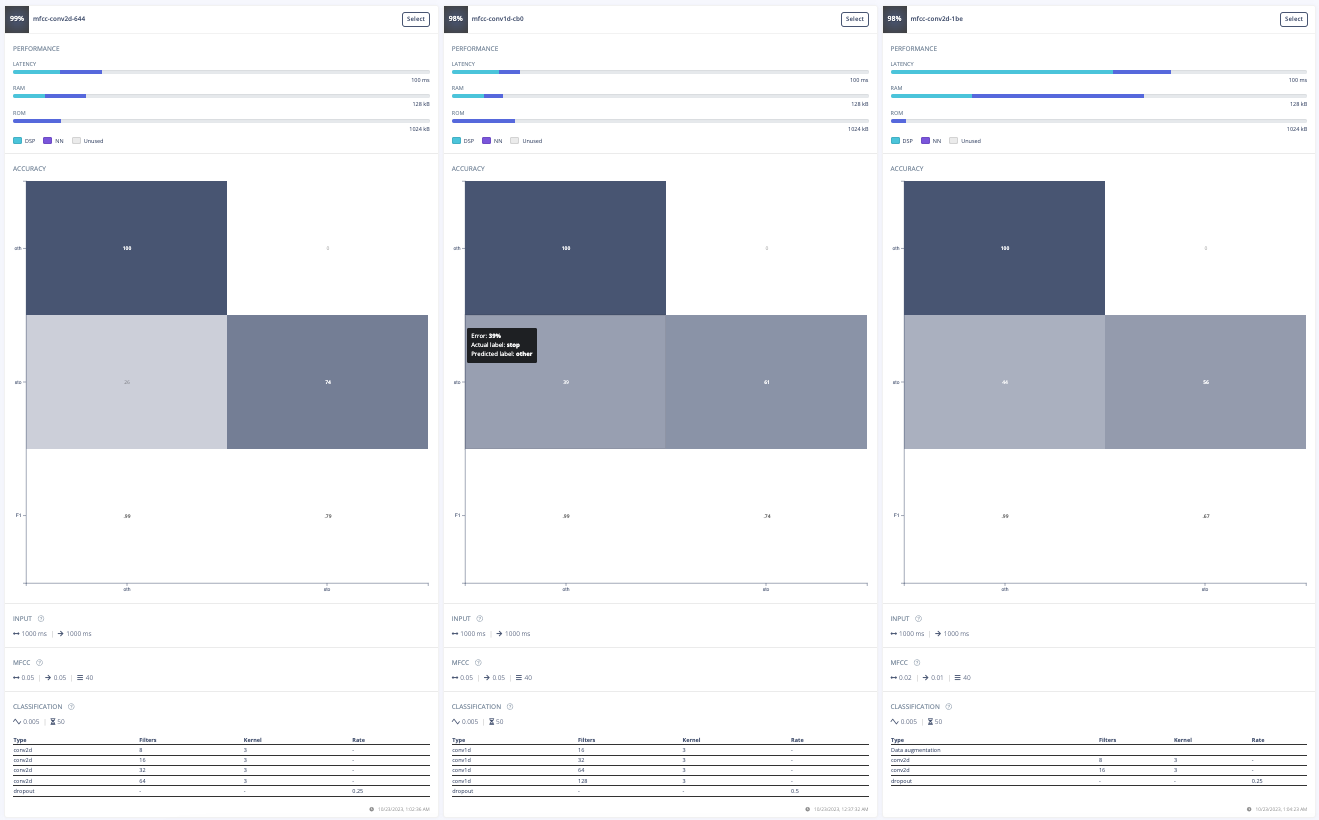
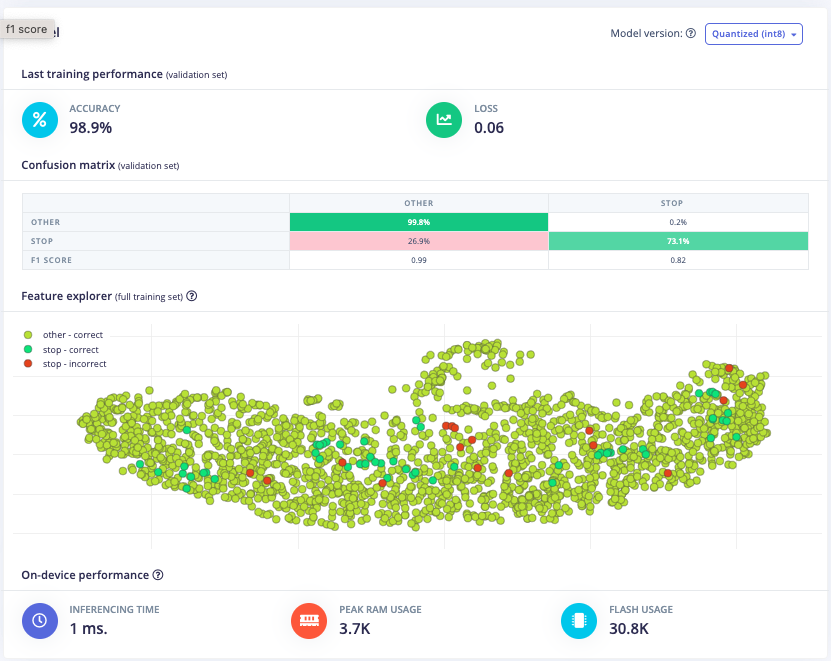
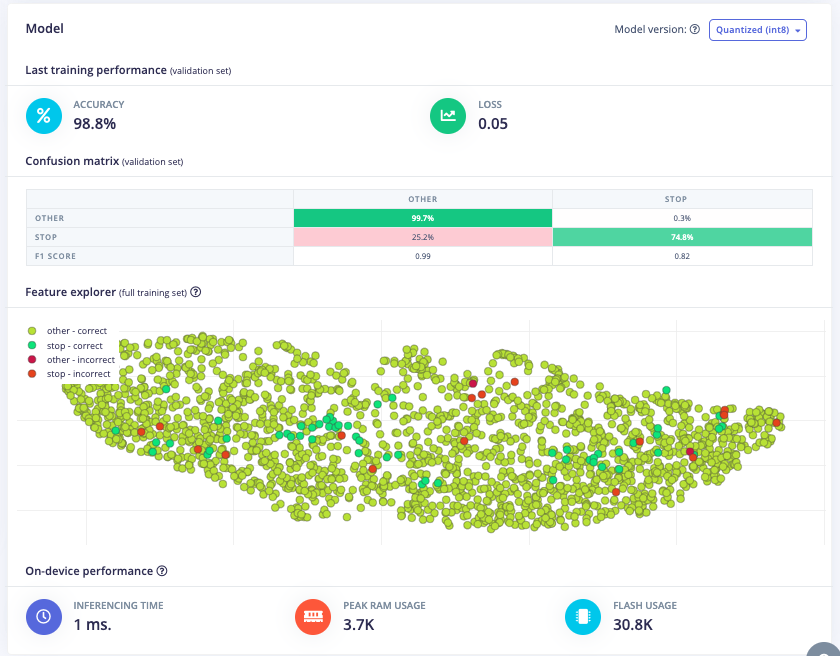
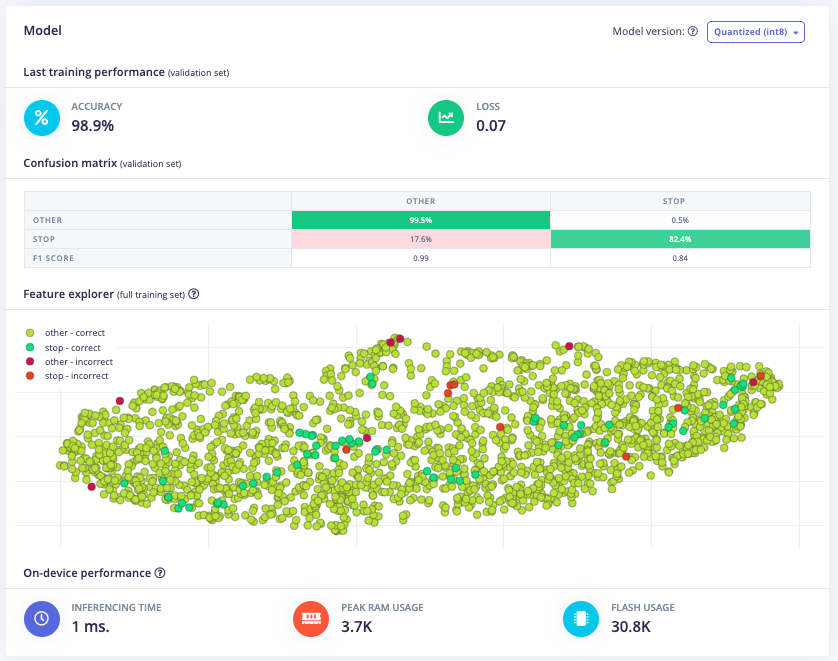
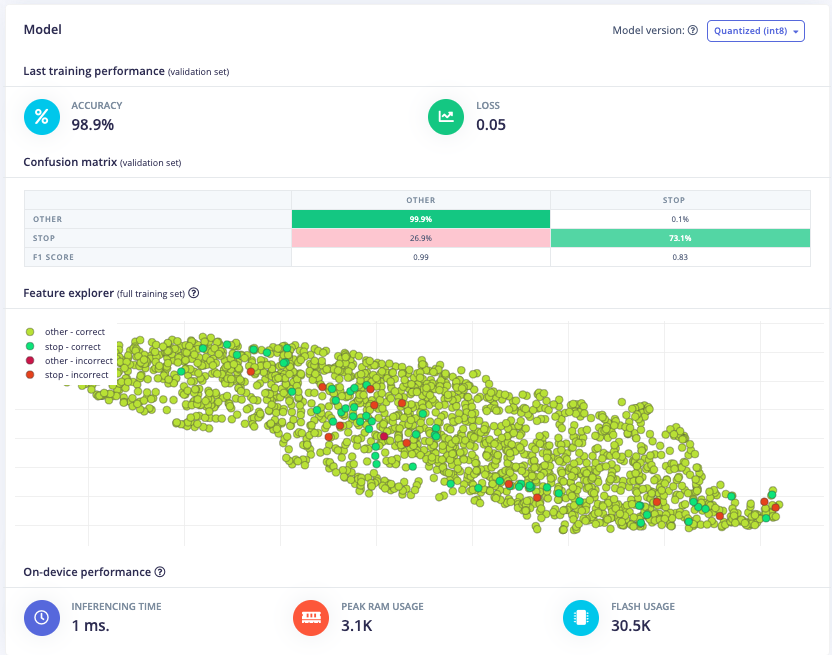
Optimized Model