MediScribe
ML Deployment Group Final Project for Harvard APCOMP215
The objective of this assignment was on the creation of a production-ready ML application. Unfortunately, a repo cannot be provided due to privacy reasons.
For this project, I was the main contributor to the backend and containerization, supporting contributor to APIs, and reviewer for the frontend.
Project Specification
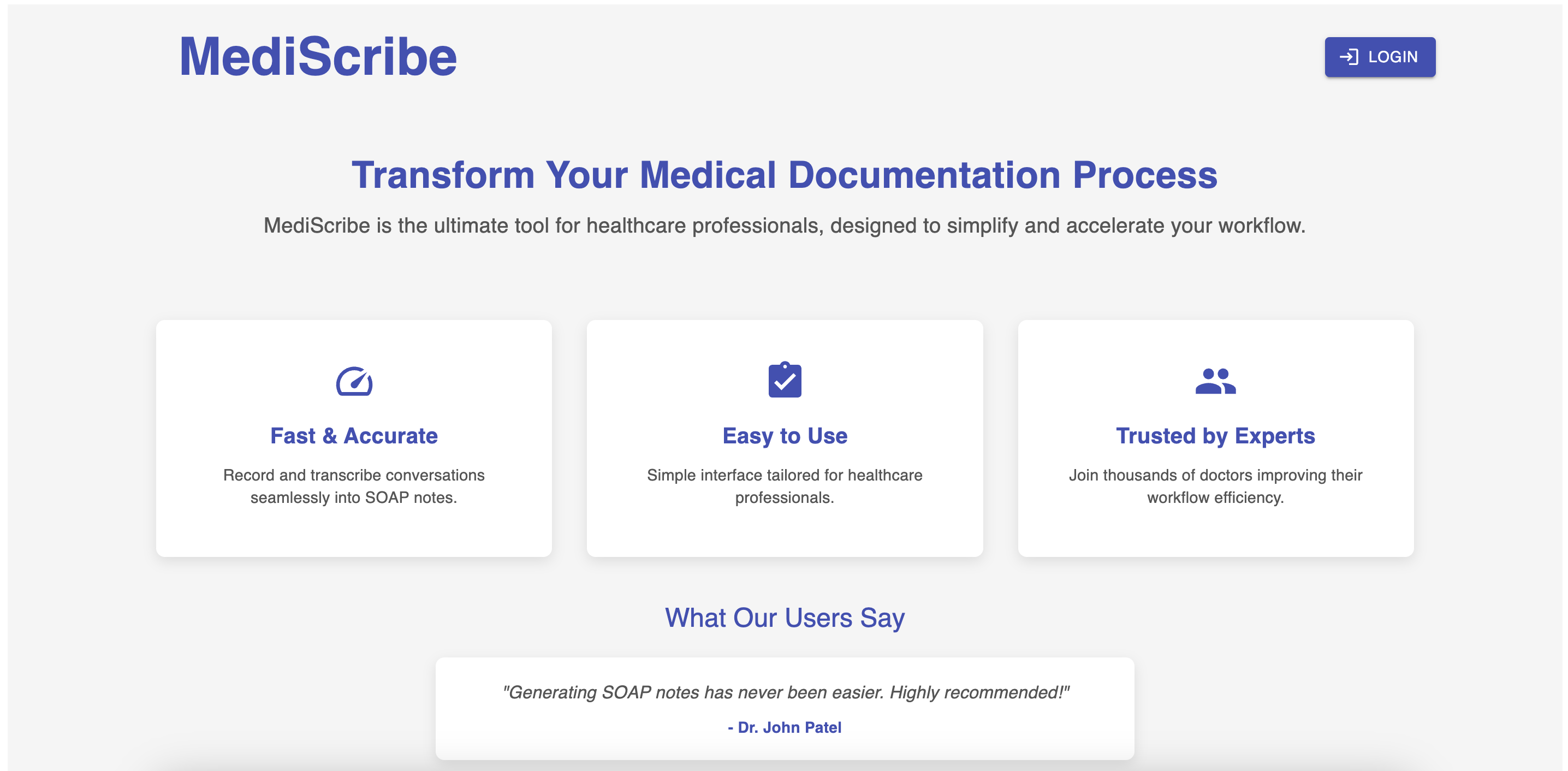
Physicians spend nearly half of their time working on electronic medical records (EMRs), averaging 16 minutes per patient on repetitive documentation tasks such as charting, ordering tests, and reviewing records. This administrative burden reduces the time available for direct patient care while also increasing the risk of documentation errors and delays. To streamline this process, we developed a web application that leverages LLMs to generate SOAP-formatted medical notes, allowing doctors to focus on treating their patients rather than manually drafting records.
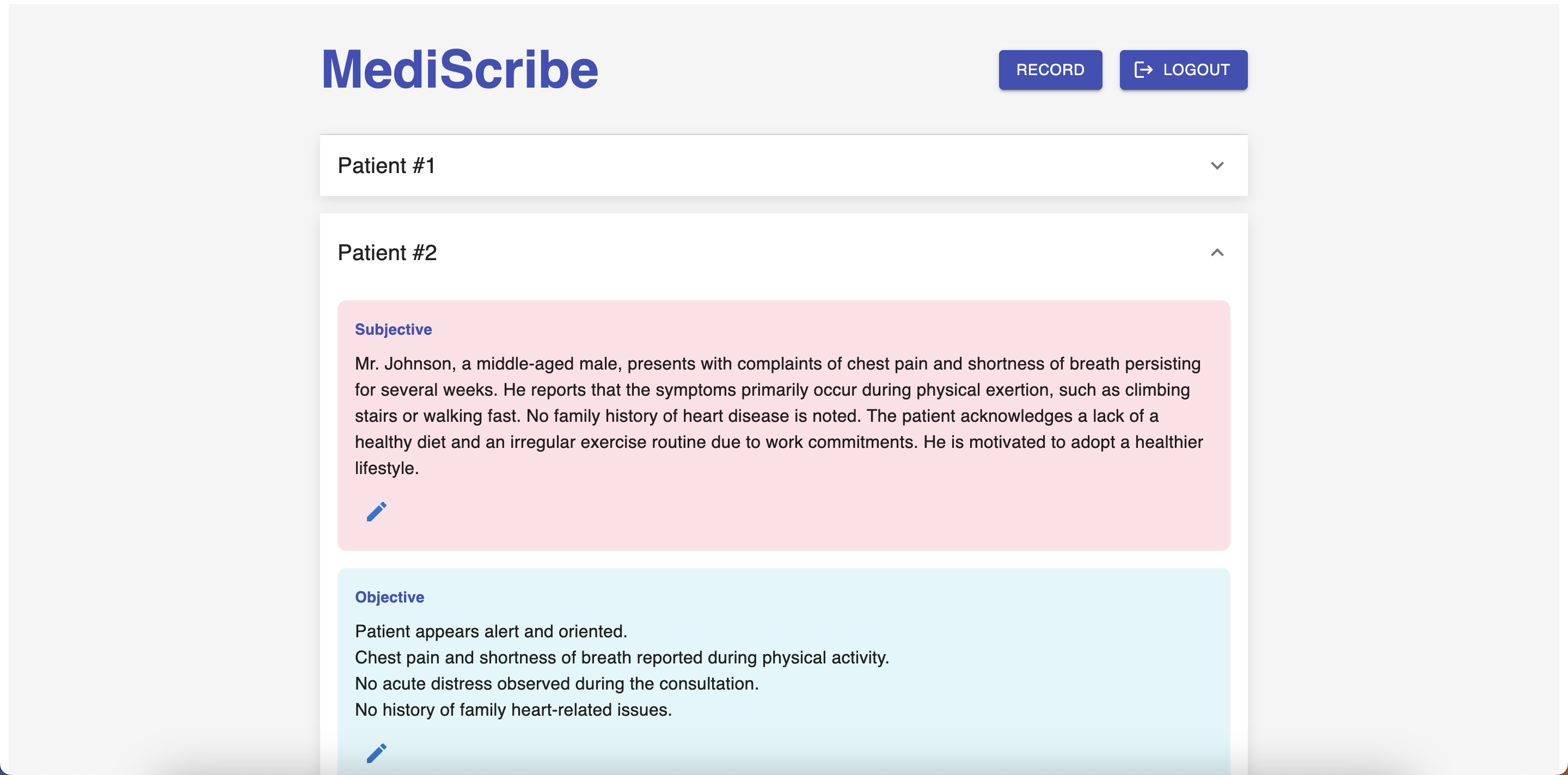
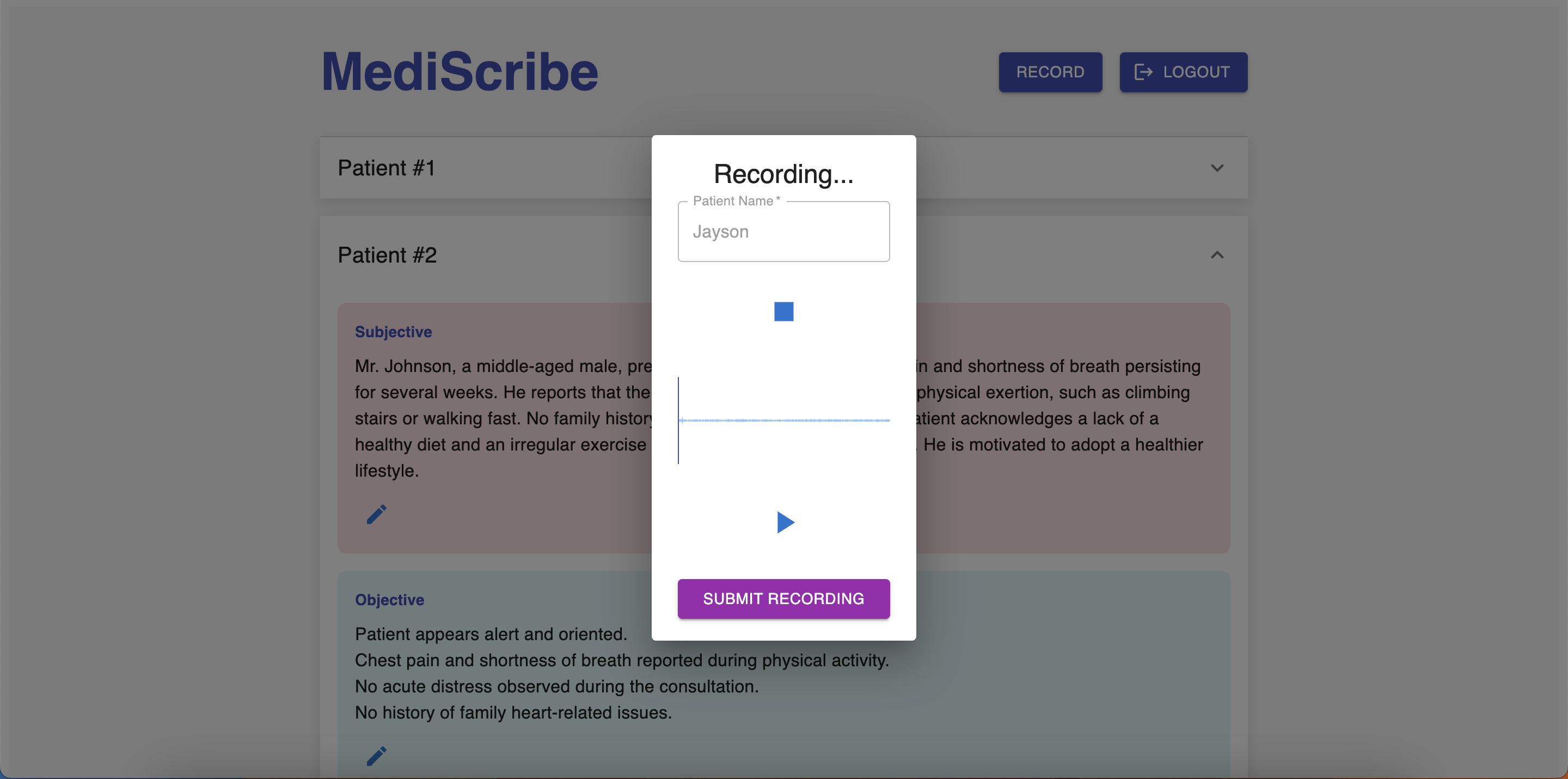
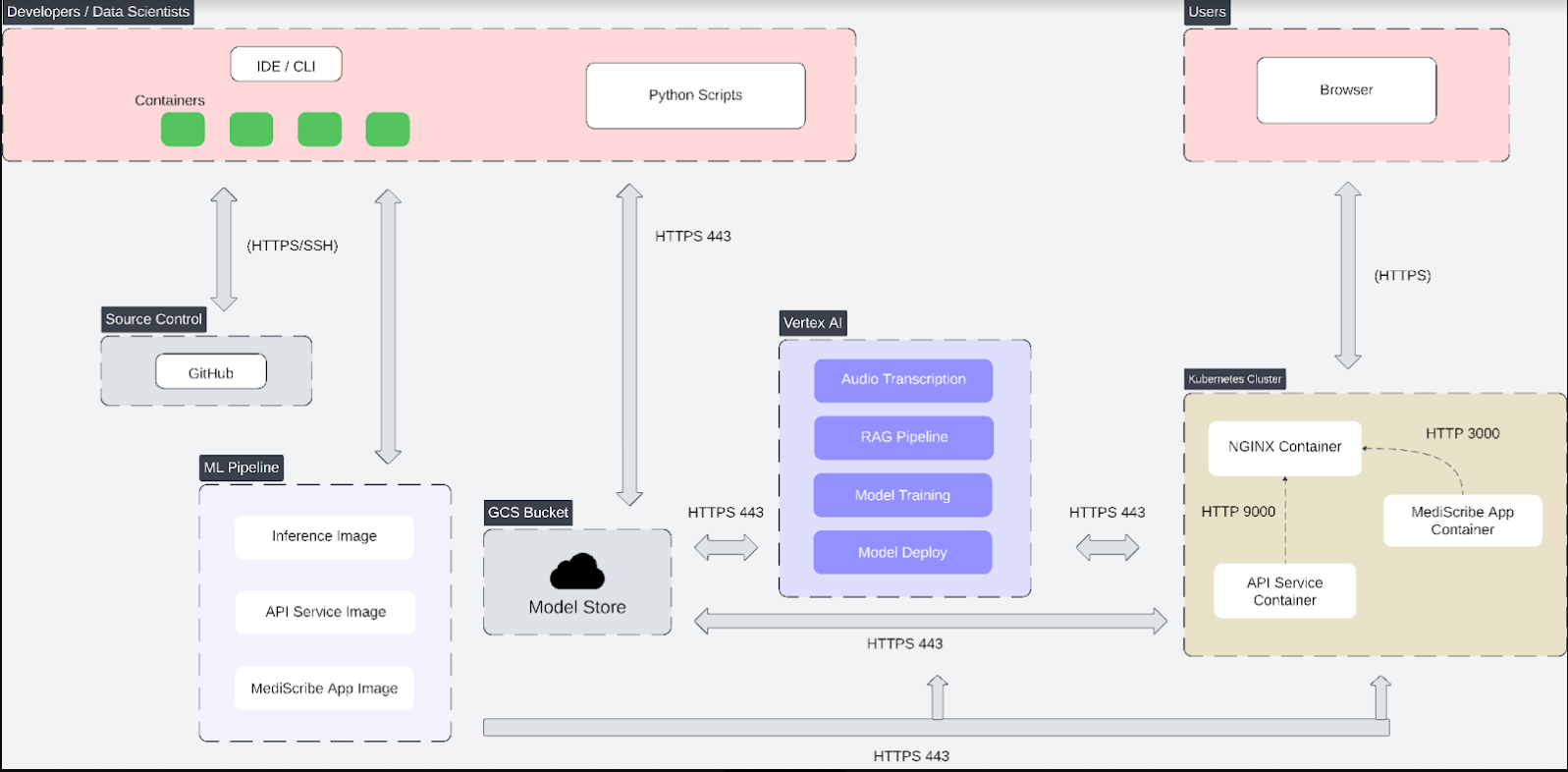
Our solution enables healthcare providers to record patient consultations and automatically generate structured medical documentation using a Retrieval-Augmented Generation (RAG) pipeline. The application consists of a React.js frontend and a Google Cloud Platform (GCP)-based backend, which is containerized using Docker and orchestrated through Kubernetes for scalability. The frontend interface allows physicians to manage patient records, initiate recordings, and review/edit automatically generated SOAP notes. When a consultation is recorded, the audio is sent to the backend for transcription and diarization before being processed into structured medical notes.
On the backend, the system is composed of five key containers:
- Fine-Tuning Container – Responsible for fine-tuning the Gemini model to generate structured SOAP-formatted medical records.
- Data Versioning Container – Uses Data Version Control (DVC) to manage and version training data.
- RAG Pipeline Container – Implements a Retrieval-Augmented Generation (RAG) pipeline to fetch relevant information from the MedCPT database, enhancing the accuracy and relevance of the generated SOAP notes.
- Transcription Container – Handles speech-to-text conversion and speaker diarization. The primary approach uses Google Speech-to-Text API for transcription and Gemini for diarization. Alternatively, Whisper and Whisper with Diarization were considered, but they require ARM architecture optimizations, whereas Google Vertex AI Pipelines currently support only x86 architectures. If adapted to a different infrastructure, Whisper models could be used for transcription and diarization, offering an open-source alternative with potentially improved performance in noisy environments.
- Inference Container – Processes the transcribed and diarized text to generate structured SOAP notes using the fine-tuned Gemini model, storing the final results in a Google Cloud bucket.
A workflow container orchestrates the end-to-end pipeline, ensuring smooth processing from transcription to final SOAP note generation. The system supports audio inputs as short as 30 seconds, though a minimum of 3 minutes is recommended for richer contextual details that improve accuracy.
Presentation Video: